What I'm Reading This Week (2025/02.23-03.01)
• By vski5 • 2 minutes readTable of Contents
Trends
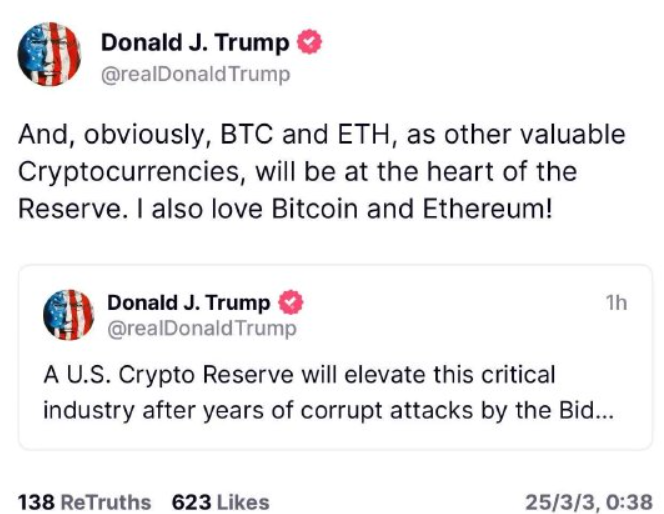
Kids, your emperor is manipulating coin prices again.
Trump tweets claiming to establish a crypto reserve: 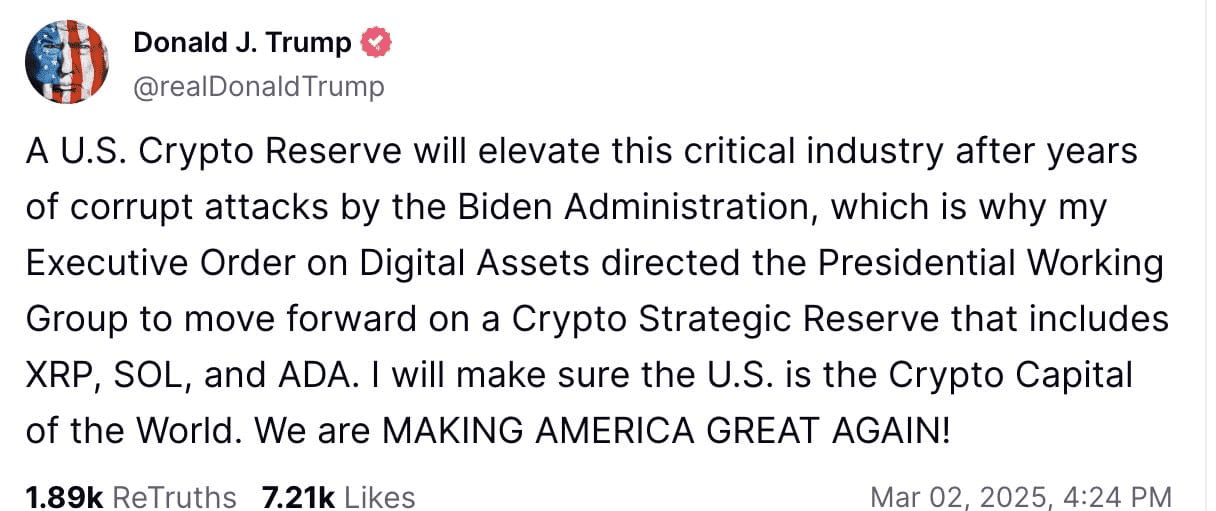
What I Am Reading
Haven’t read any books
0. When you feel a lot of pressure, just take a look at Zelensky
- A national leader humiliated live at the White House, though it’s self-inflicted
- Vance did what a childless cat lady would do, seeking emotional value—blaming Zelensky for not thanking America
- China, the US, and Russia rarely reach a consensus, supporting a ceasefire in Ukraine
- Uncertain whether Ukraine will be carved up, and what Europe will do next
1. A Week of DeepSeek Releasing New Stuff
Day 1: FlashMLA
- Released FlashMLA - an efficient MLA decoding kernel for Hopper GPUs
- Optimized for variable-length sequences, now in production
- Supports BF16
- Supports paged KV cache (block size 64)
- Performance: 3000 GB/s memory-bound, 580 TFLOPS compute-bound (based on H800)
Day 2: DeepEP
- Released DeepEP - the first open-source EP communication library for MoE model training and inference
- Features:
- Efficient and optimized all-to-all communication
- Supports intranode (NVLink) and internode (RDMA) communication
- High-throughput kernels for training and inference prefilling
- Low-latency kernels for inference decoding
- Native FP8 dispatch support
- Flexible GPU resource control for computation-communication overlapping
- Features:
Day 3: DeepGEMM
- Released DeepGEMM - an FP8 GEMM library supporting dense and MoE GEMMs
- Applied to V3/R1 training and inference
- Performance: Up to 1350+ FP8 TFLOPS on Hopper GPUs
- Features:
- No heavy dependencies, as clean as a tutorial
- Fully Just-In-Time compiled
- Core logic at ~300 lines, outperforming most expert-tuned kernels
- Supports dense layout and two MoE layouts
Off-Peak Discounts Alert
- DeepSeek API Platform off-peak discounts
- Time: Daily 16:30–00:30 UTC
- Discounts:
- DeepSeek-V3: 50% off
- DeepSeek-R1: 75% off
- Goal: Optimize resource utilization and save costs
Day 4: Optimized Parallelism Strategies
- Released optimized parallelism strategies
- DualPipe:
- A bidirectional pipeline parallelism algorithm for computation-communication overlap in V3/R1 training
- Link: https://github.com/deepseek-ai/DualPipe
- EPLB:
- An expert-parallel load balancer for V3/R1
- Link: https://github.com/deepseek-ai/eplb
- Analysis:
- Computation-communication overlap analysis for V3/R1
- Link: https://github.com/deepseek-ai/profile-data
- DualPipe:
Day 5: 3FS, Thruster for All DeepSeek Data Access
- Released 3FS (Fire-Flyer File System) - a parallel file system
- Fully utilizes the bandwidth of modern SSDs and RDMA networks
- Performance:
- 180-node cluster: 6.6 TiB/s aggregate read throughput
- 25-node cluster GraySort benchmark: 3.66 TiB/min throughput
- Per client node KVCache lookup peak: 40+ GiB/s
- Features:
- Disaggregated architecture with strong consistency semantics
- Supports training data preprocessing, dataset loading, checkpoint saving/reloading, embedding vector search, and inference KVCache lookups for V3/R1
- Links:
- 3FS: https://github.com/deepseek-ai/3FS
- Smallpond (data processing framework based on 3FS): https://github.com/deepseek-ai/smallpond
Day 6: DeepSeek-V3/R1 Inference System Overview
- Released an overview of the DeepSeek-V3/R1 inference system
- Optimized throughput and latency:
- Enhanced batch scaling via cross-node EP
- Computation-communication overlap
- Load balancing
- Online service statistics:
- Per H800 node: 73.7k/14.8k input/output tokens per second
- Cost profit margin: 545%
- Goal: Provide value to the community and contribute to AGI goals
- Deep Dive: https://bit.ly/4ihZUiO
- Optimized throughput and latency:
Link
Original text hyperlink and QR code