What I'm Reading This Week (2024/11.03-11.09)
• By vski5 • 9 minutes readTable of Contents
Trends
No trends this week
What I’m Reading This Week (2024/11.03-11.09)
Good morning, this is the second week of November 2024.
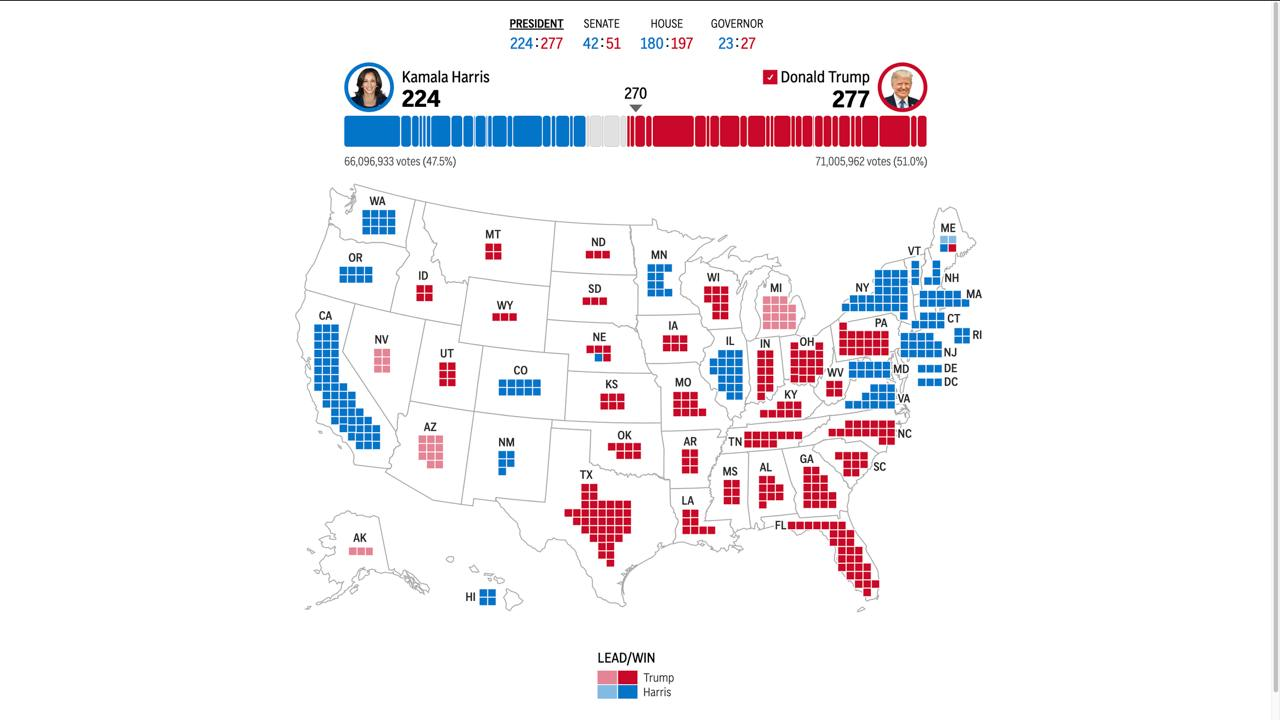
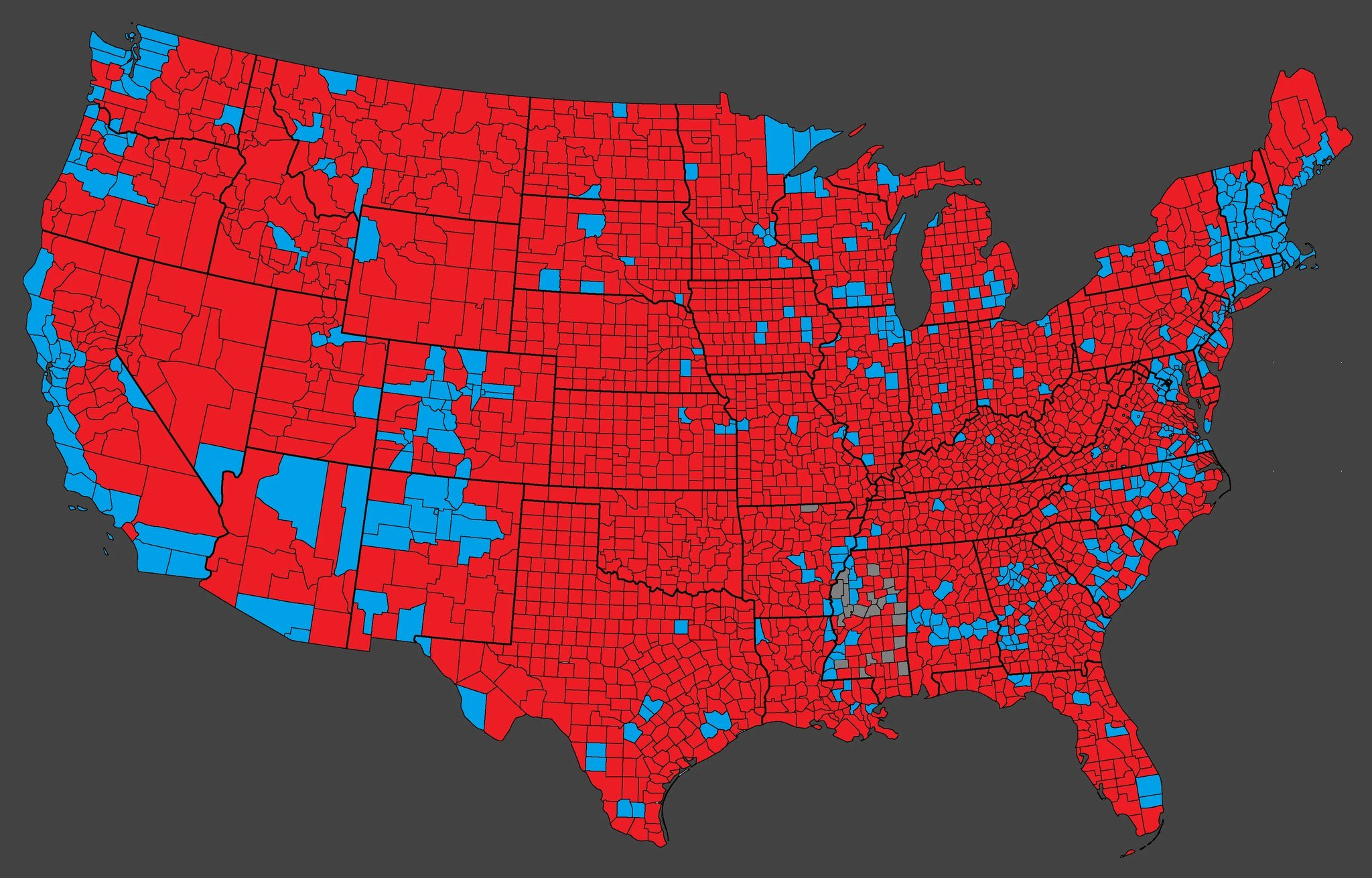
Focus of the week: The US election results were unexpected, with Trump defeating Harris by an overwhelming margin.
This unexpected result caught prediction markets off guard. Trump’s vote share in key swing states significantly exceeded market expectations.
There are two interesting points about this election:
First, there is a significant disconnect between the volume of mainstream media, self-media and Democratic supporters and actual public opinion. This is reflected in two aspects:
- The contrast between public opinion and election results: Although these voices dominate social media and news platforms, according to election data analysis, Trump maintained a stable and significant lead in support across multiple key states, which stands in stark contrast to mainstream media narratives.
- The divide between elites and ordinary people: As JD Vance described the “Childless Cat Ladies” - this group has severe cognitive differences from ordinary people. They control media discourse but often stand in opposition to mainstream values. This divide is evident in many events, such as during disasters when they focus more on rescuing pets than human lives, and prefer symbolic mourning ceremonies over actual relief efforts. This reflects their unique stance on “who deserves to be treated as human” - where people of black, white or yellow races are not considered human, only those who fit their needs are human, they are covert, thorough self-interested individuals who package themselves at the moral high ground.
Second, the pricing mechanism in prediction markets malfunctioned. The odds trends on notable event contract platforms Polymarket and IBKR indicate that the market severely underestimated Trump’s chances of winning. However, a top arbitrageur accurately captured this mispricing and earned substantial returns through large bets. When the first batch of massive bets totaling $28 million appeared on the blockchain, many self-media outlets expressed shock at the size of the wagers, failing to recognize that this was actually a prediction arbitrage based on in-depth analysis. However, the profits likely went far beyond this - after the election, Chainalysis analysts estimated that this ‘Whale’ Théo actually made $83.5 million in profits.
This article will further analyze the systemic flaws in prediction markets and how “smart money” exploits market inefficiencies to generate excess returns.
https://apnews.com/hub/election-2024
1. US Election Special Section
1. “Smart Money” Betting on Trump on Polymarket
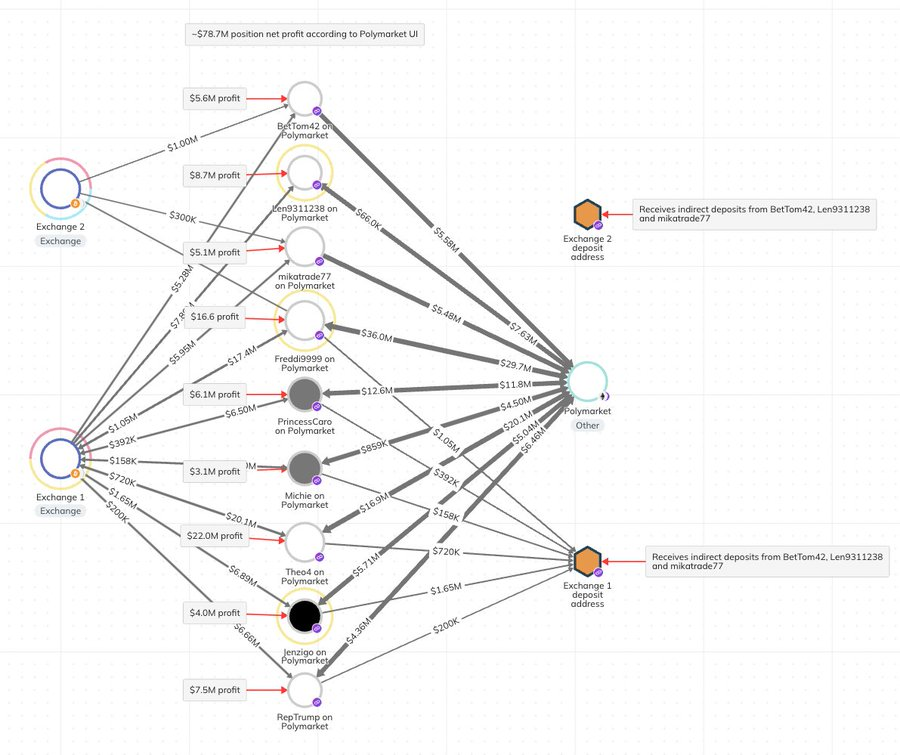
- Before the 2024 US presidential election, four Polymarket accounts owned by non-US citizens placed large bets predicting Donald Trump’s victory, with total bets exceeding $30 million.
- According to the Wall Street Journal, these bets were led by a mysterious figure named Théo, who was expected to earn nearly $50 million from these wagers.
2. Théo’s Strategy
Théo proposed a strategy different from traditional polls, believing they underestimated Trump’s support.
- Neighbor Polling: Théo suggested a new polling method called “neighbor polling,” which asks respondents who they think their neighbors would support. The core idea is that while respondents might be reluctant to reveal their own political preferences, they can indirectly reveal them by guessing their neighbors’ voting choices.
Effects of Neighbor Polling:
- Théo cited several public polls comparing results between “neighbor polling” and traditional methods, finding Trump’s support significantly higher in neighbor polls than traditional expectations.
- Théo believed this indicated traditional polls weren’t accurately capturing Trump supporters’ true attitudes.
Beyond public polling data, Théo commissioned private research from a prominent polling company, showing Trump’s support far exceeded general poll expectations. Though the results weren’t public, Théo maintained this data strengthened his confidence in Trump’s victory.
3. Betting on Polymarket
Théo’s Bets:
- Théo used 11 anonymous accounts on Polymarket, including usernames like Fredi9999, Theo4, PrincessCaro, and Michie.
- Among these, Fredi9999 and Theo4 rank as the top two most profitable accounts in Polymarket history, while PrincessCaro and Michie rank eighth and fourteenth respectively.
Market Response:
- At the time, the market assessed Trump’s chances of winning the popular vote at below 40%, but Théo saw this as underestimating Trump’s support.
- Through these strategic bets, Théo ultimately achieved massive returns on election night.
According to Chainalysis’s latest update:
- A 10th address linked to Théo was confirmed, increasing his estimated total profit by $4.8 million to reach $83.5 million.
- Additionally, an 11th address might bring an extra $2.1 million in profits, though this information remains unconfirmed.
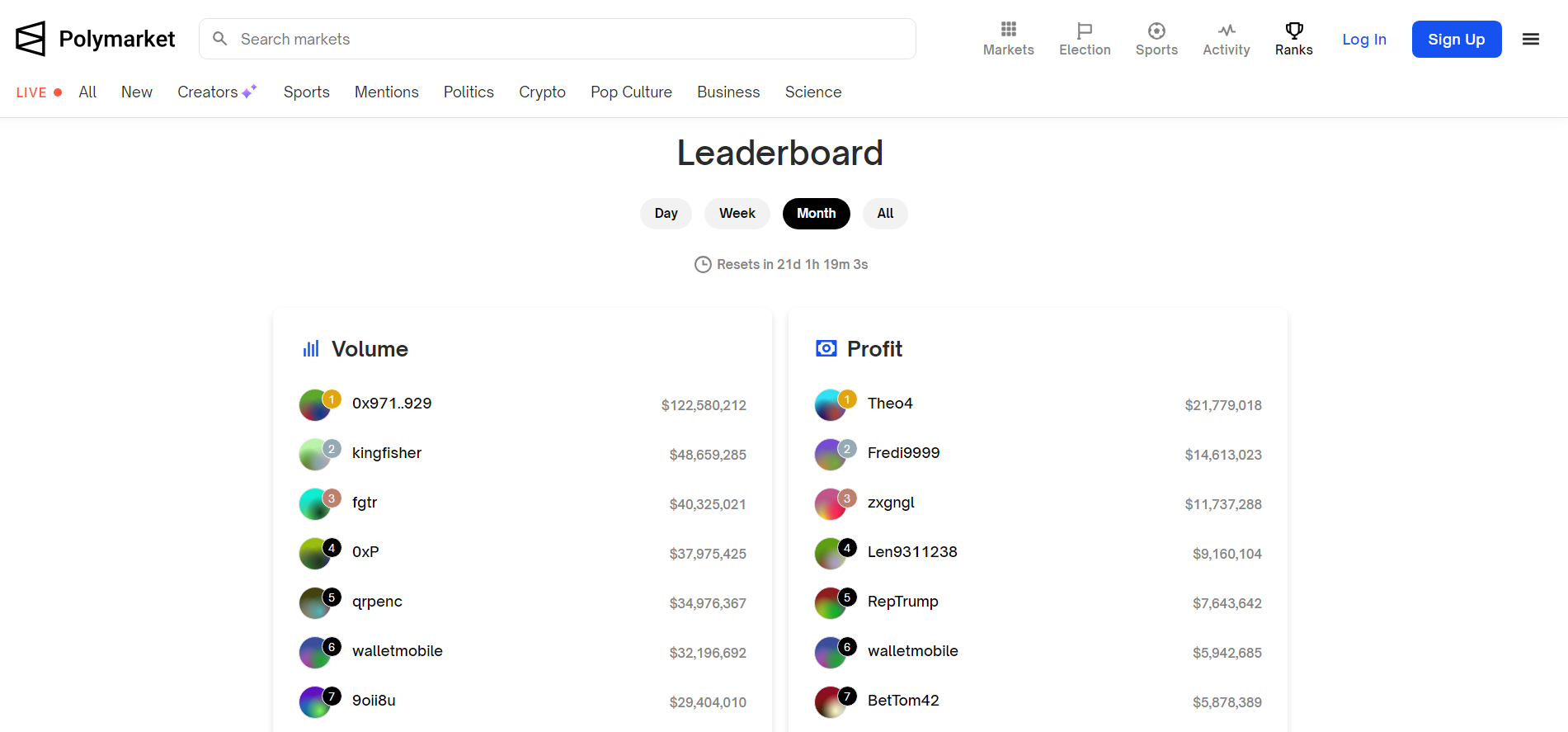
Polymarket’s Real-time Rankings
- This month’s highest profit earner is Théo.
2.False Positives in eBay’s A/B Testing
- A/B testing is widely used in the software industry to evaluate ideas and establish causality.
- It is considered the gold standard for determining whether changes in the treatment caused changes in the metrics of interest.
- Software experiments differ from experiments in other domains due to their scale and the small effect sizes that matter to businesses.
- For instance, large companies may launch over 100 experiment treatments in a single workday.
- A 3% improvement in conversion rate is considered a significant achievement.
- Most experiments fail to improve key metrics, with success rates typically around 10-20%.
- The industry standard alpha threshold of 0.05, combined with low success rates, implies a high probability of false positives.
- A false positive occurs when a statistically significant result is observed (rejecting the null hypothesis), but the true treatment effect is not inconsistent with the null hypothesis, given the sample size.
Costs of False Positives and False Negatives
- False positives can be expensive in software development as they can lead to pursuing wrong ideas and misdirecting the roadmap or backlog.
- While false negatives (missing good ideas) also have a cost, they are generally considered less expensive than false positives.
- False negatives are likely to occur for ideas with effects near the minimum detectable effect.
- Organisations typically run multiple experiments with variations before abandoning an idea, reducing the probability of all variations being false negatives.
Estimating the False Positive Risk (FPR)
- P-values are often misinterpreted as the probability of making a mistake when choosing the treatment over the control when a statistically significant difference is observed.
- The p-value is actually the probability of obtaining a result equal to or more extreme than what was observed, assuming the null hypothesis is true.
- The False Positive Risk (FPR) is the probability that a statistically significant result is a false positive, meaning the null hypothesis is true despite the significant result.
- FPR is also sometimes called the False Discovery Rate (FDR).
- The FPR can be estimated using Bayes Rule and requires knowing the prior probability of the null hypothesis.
Estimating the Success Rate
- An observed success (“win”) in an experiment does not necessarily mean a true success, where the true effect is large enough to reject the null hypothesis.
- Several approaches can be used to estimate the true success rate from the observed win rate:
- Naïve Approach: Simply using the win rate as the success rate, ignoring both false positives and false negatives.
- Replicated Experiments: Replicating experiments with borderline p-values to increase statistical power and reduce false positives.
- Conditional Probabilities: Using conditional probabilities based on alpha, power, and the observed statistically significant rate to estimate the true success rate.
Choosing Alpha
- Organisations should carefully consider the appropriate alpha level based on the cost of false positives and false negatives.
- Lowering alpha can be more efficient in reducing FPR than increasing power.
Replicating or Extending Experiments
- Given the high FPR of experiments with p-values near the alpha threshold, replication or extension can be used to validate results.
- Extending an experiment can reduce the FPR at a small cost to agility.
- Using sequential group testing with interim analysis can further control the type-I error rate and potentially allow for early stopping.
Success Rate of Ideas vs. Experiments
- The failure rate of ideas is not the same as the failure rate of experiments.
- An idea can be evaluated over multiple experiments, with iterations and modifications based on previous results.
- The success rate of experiments might decrease over time as organisations gain trust in their experimentation platform and increase agility, potentially at the cost of exposing users to more bugs.
Summary
- The FPR is a more intuitive metric than p-values for understanding the risk of false positives in A/B testing.
- Organisations should consider the success rate, the cost of false positives and false negatives, and the potential benefits of replication or extension when deciding on their A/B testing practices.
- Lowering alpha and using sequential group testing can help reduce FPR and improve the reliability of A/B testing results.
3. Weighted Z-Test in eBay’s A/B Testing
At eBay, experimenters often conduct multiple A/B tests for the same hypothesis.
- This may be due to the need to collect multiple rounds of samples.
- It could also be to verify surprising experimental results.
- Sometimes, separate experiments are conducted for different eBay sites or channels.
Combining the results of these multiple experiments can improve the power of statistical analysis.
Traditionally, Fisher’s meta-analysis method was used, but it’s limited to one-sided tests.
eBay uses a method called “weighted z-test” that can be used for both one-sided and two-sided tests.
This method combines multiple experiment readings such as p-values, lift, and confidence intervals.
The weighted z-test offers several benefits:
- Increased Statistical Power: By combining data from multiple experiments, weighted z-test can detect smaller effects.
- Smaller Confidence Intervals: This leads to more precise estimates of effect size.
- Fewer False Positives: Combined analysis is less likely to produce statistically significant results when there’s no real effect.
The weighted z-test uses experiment-specific weights to combine results.
- These weights are chosen to maximize test power.
- Weights are proportional to the expected difference between null hypothesis and reality.
- They are inversely proportional to the standard deviation of the statistic used in each experiment.
Simulations show that weighted z-test achieves better power than simply pooling all samples together.
- This is especially true when there’s heterogeneity in data variance.
Applying Weighted Z-Test at eBay
- To use weighted z-test, combined experiments must meet certain assumptions:
- All experiments must test the same hypothesis.
- Statistical tests must be independent of each other.
- Specifically, eBay uses six checks to ensure these assumptions are met:
- Data collection must be complete.
- No quality issues violating best practices.
- Equal traffic allocation ratio between treatment and control groups.
- No shared control groups between any two experiments.
- Difference in experiment duration not exceeding one week.
- Difference in experiment start dates not exceeding three months.
- When experimenters request to combine experiment results, eBay’s Touchstone platform automatically checks these conditions.
- Once these checks pass, weighted z-test can be used to calculate combined test statistics.
- To use weighted z-test, combined experiments must meet certain assumptions:
Example of eBay’s Weighted Z-Test
- The article provides an example where experimenters wanted to measure the impact of removing product recommendation deduplication rules on product detail pages.
- Separate experiments were conducted for eBay website and native applications.
- The article outlines steps for combining these two experiment results using weighted z-test.
- Calculate standard error for each experiment.
- Calculate weights for each experiment.
- Calculate combined z-statistic.
- Calculate combined p-value.
- Calculate combined lift, confidence intervals, and means.
- By combining experiments, confidence intervals decrease, making analysis more sensitive.
Conclusion
- Weighted z-test is a valuable tool for improving the power of eBay’s A/B testing.
- It allows experimenters to combine results from multiple experiments, making it easier to detect subtle signals.
Link
Original text hyperlink and QR code